
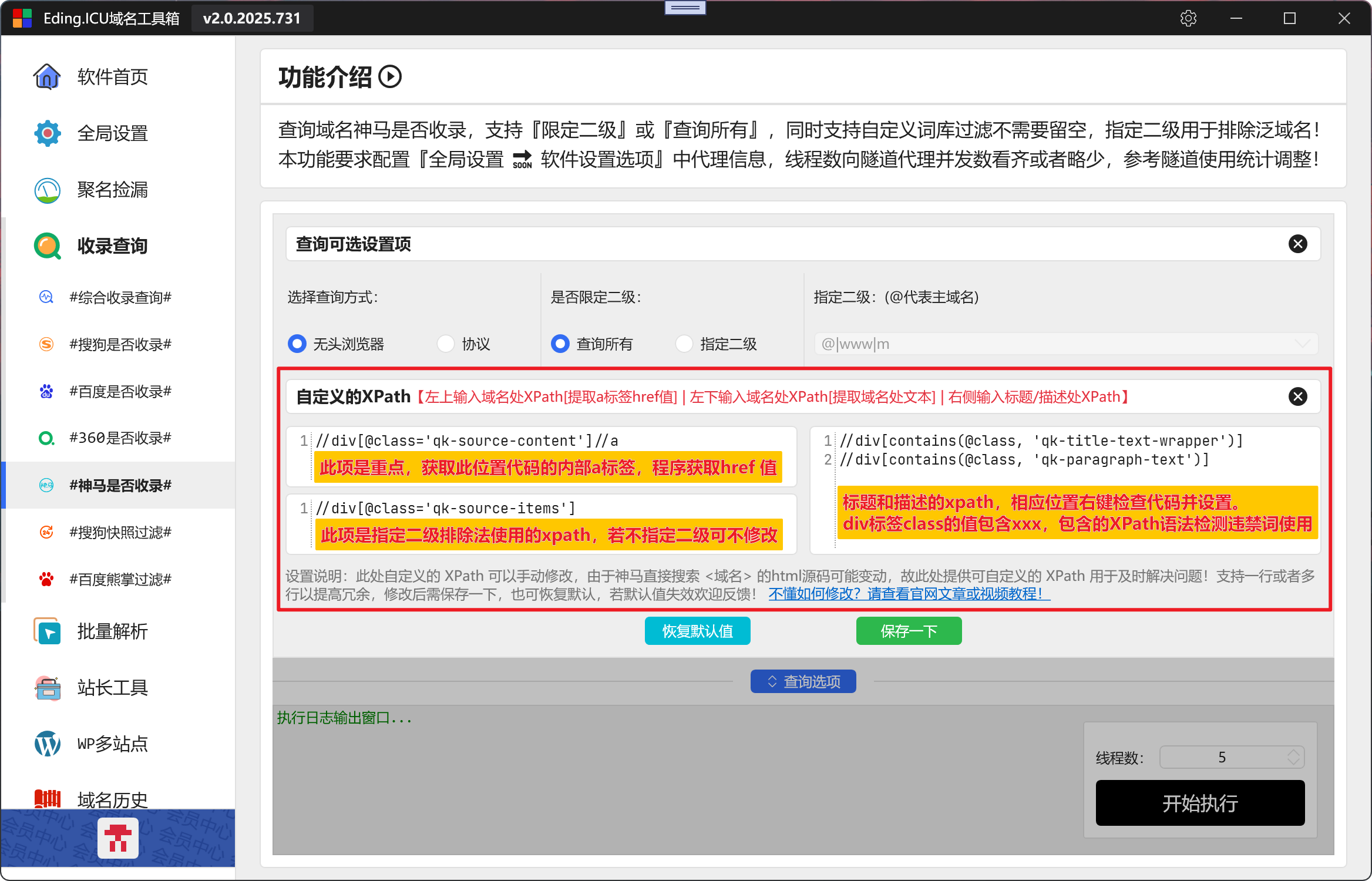
如上图,此处的XPath可以自定义修改,以下教大家如何修改
本工具批量查询神马,通过直接搜索
<域名>获取首页的html源码(不翻页)并进行判断,通过自定义的XPath获取指定位置的代码的a标签,程序会自动获取此a标签的href值,检测是否为包含当前查询的域名即为神马已收录域名。多说一句,神马不支持
site:<域名>搜索,故变通了一下只搜索域名,获取第一页相应位置是否有此域名,无论是中文还是域名均可检测出来。2025.10.15更新:神马特别支持
http://<域名>、https://<域名>、<域名>三种输入方式,判断时程序自动去除协议等前缀进行匹配,加上http://等效果更佳,欢迎体验。
以下使用 baidu.com 做演示
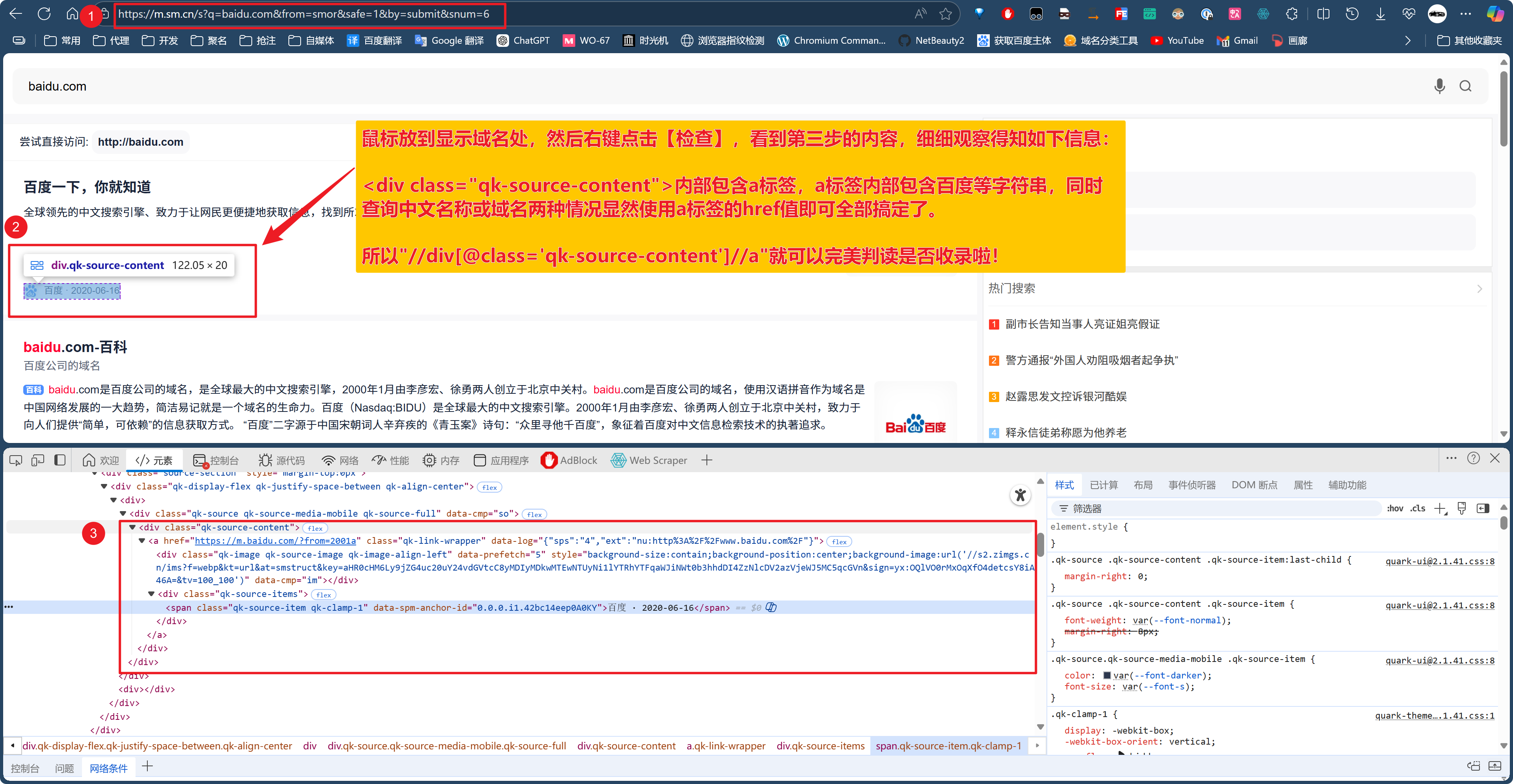
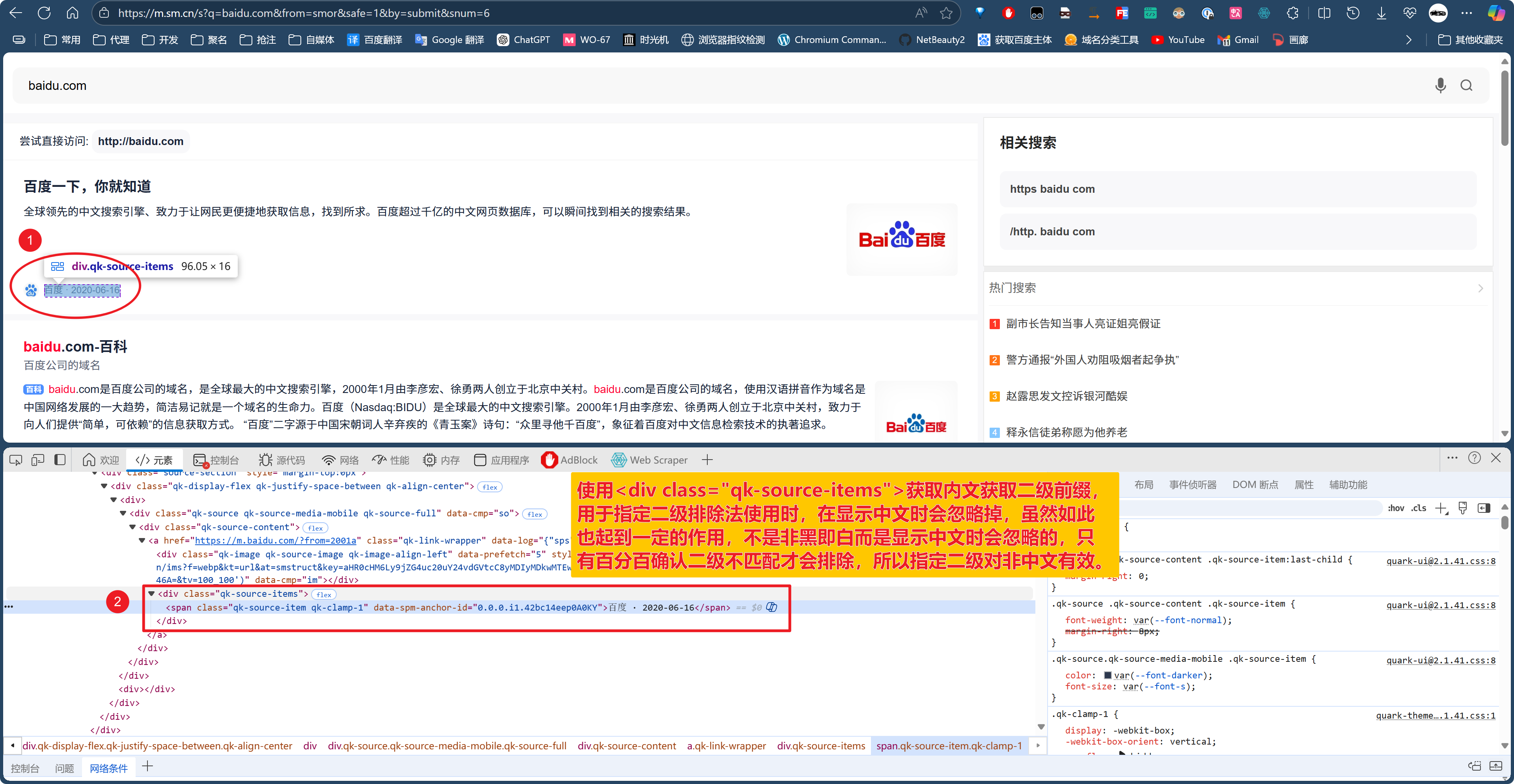
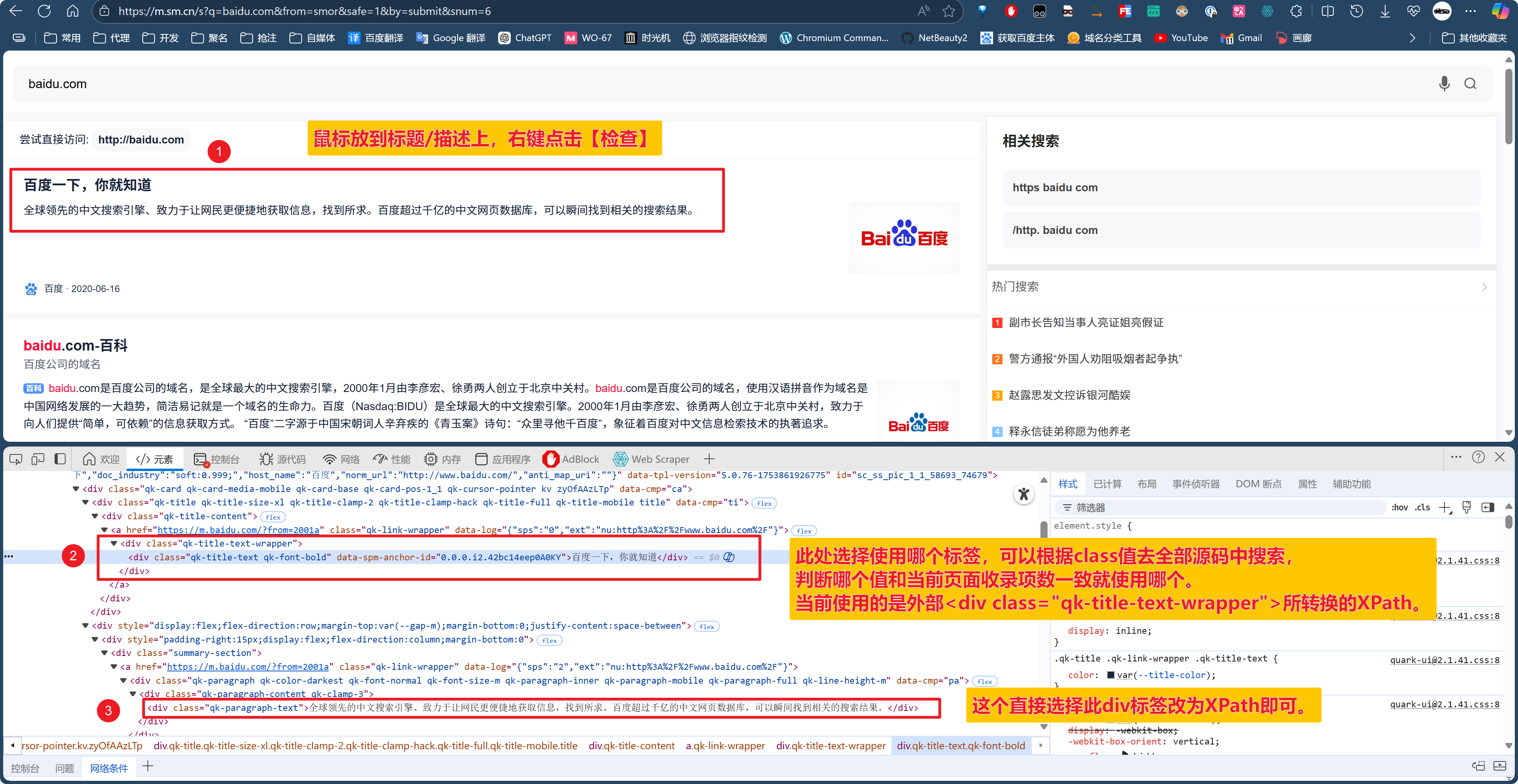
请查看以上图片!
说明:当前神马需要自定义的XPath有三项需要设置,左上即第一项最为重要,用于判断是否收录,经过分析使用a标签的href值可以准确判断中文与域名两种显示内容。左下项用于指定二级选项使用,对域名显示百分百准确,中文显示则忽略。右侧项则用于违禁词判断使用,不适用违禁词可不修改。当然,指定二级选项不使用也可不修改。
除了百度,其他家很少更新html页面源码结构,自定义XPath功能一般很少修改,若失效可以反馈给我修改最为合适,欢迎失效了群内反馈哦。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
评论(0)